Kai Fronsdal AI Researcher
Can AI Self-Correct? Analyzing the Limitations of Large Language Models
19 Mar 2024This post is a summary of this research paper writen as a final project for Stanford’s CS 224N and Intro to AI Alignment classes.
As models become more and more powerful, they have started to approach or exceed human-level performance on a variety of tasks. In order to train these models, researchers have been using increasingly large datasets and more compute. However, as these model approach human limits, it becomes harder and harder to improve them from human feedback.
The natural solution is to replace the human feedback with model feedback; that is, to have the model evaluate its own outputs and make necessary amendments. There are several varients to this process, including RLAIF1 and Constitutional AI2, but the basic idea follows the following abstract process:
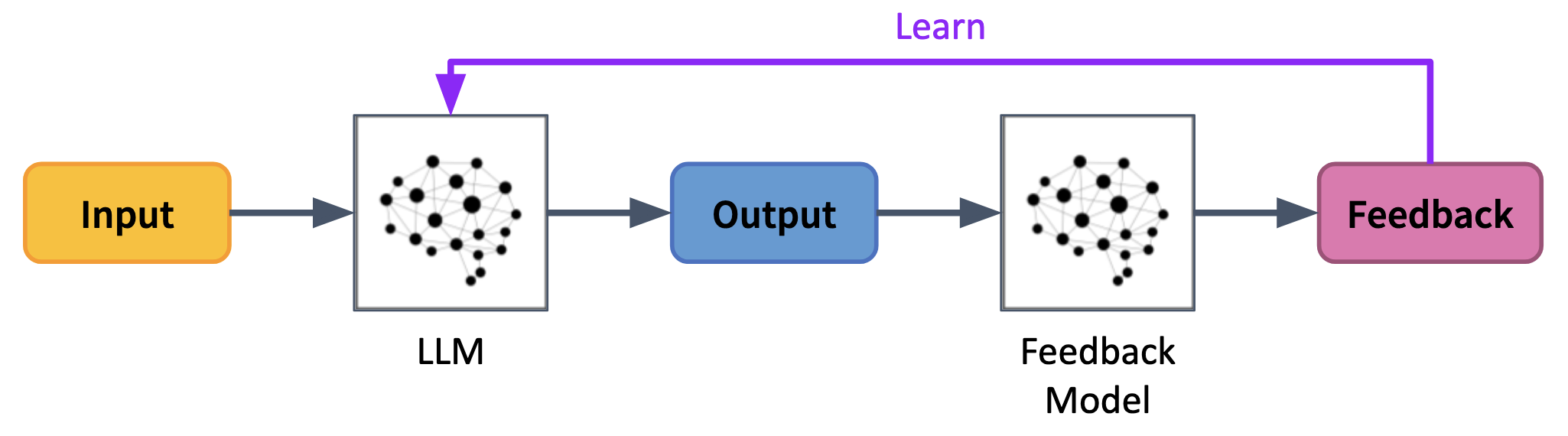
However, this method operates under the assumption that the feedback is actually aligned. Researchers have shown that these models can be easily swayed by biased feedback, which might hint at a fundamental deficit in their ability to self-correct and result in runaway feedback loops if used in an RLAIF pipeline.
I wrote a faster c++ sorting algorithm
25 Dec 2023These days it’s a pretty bold claim if you say that you invented a sorting algorithm that’s 10% faster than state-of-the-art. You’ll quickly find that the advice on every stackexchange post asking for the “fastest sorting algorithm” is always to just use std::sort. Recently, with C++17 introducting support for parallelism, sorting performance has skyrocketed by running on all available cores. It is not hard to find algorithms that achieve 10x performance by using SIMD parrallelism or 19x by using multiple cores.
However, all of these optimizations are based around std::sort which is designed to only work for std::random_access_iterator and is not designed to work for std::forward_iterator. This is a problem because many of the most popular data structures in C++ are not random access. For example, std::list is a doubly linked list and std::forward_list is a singly linked list. Instead, these datastructures implement their own sorting algorithms, but they tend to be bandaid patches to the standard merge sort to make the linked lists appear more like random access iterators. We will explore the current implementation of list::sort and then propose a few optimizations to make it faster.
Top Trees: A Generic Data Structure for Tree Augmentations
13 Jun 2022This paper was written for CS166: Data Structures at Stanford University. Top Trees are a very cool and flexible data structure that can be used to solve a variety of dynamic forest problems very quickly (asymptotically at least) with a simple interface. However, the papers/thesis on this data structure are all over 100 pages long and are very dense. This paper is an attempt to distill the essence of the data structure and the runtime into a more pedegocially digestible form. Additionally, the paper concludes with a potential extension to directed acyclic graphs (DAGs) which is not covered in the original papers.
Older
Newer